1. Data Collection:
The dataset consists of pre- and post-event satellite imagery partitioned into multiple tiles. Initially in
GeoTiff format, each tile is converted to JPG to reduce storage consumption. With a total of 21,460 tiles,
including both pre- and post-event images, we generated OpenStreetMap and GoogleMap representations for each
tile by aligning and matching raster layers in QGIS. Additionally, building footprint information was
extracted by aligning shapefile raster layers with the GeoTiff dataset.
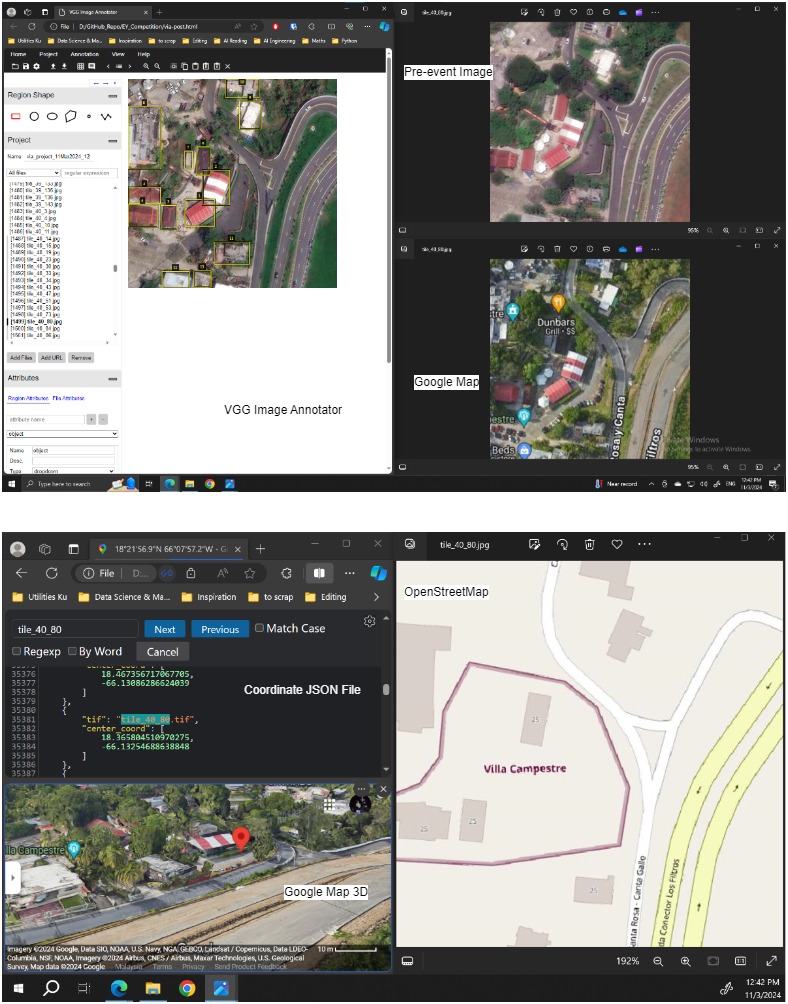
Manual filtering was performed to select only images with mixed areas of residential and commercial zones.
Furthermore, we extracted center coordinates for each tile and leveraged them to access 3D views of the
corresponding areas on Google Maps. This enabled us to label all the buildings with high confidence by
cross-checking building classes from multiple references.
All tiles were then distributed among team members for manual annotation using VGG Image Annotator and in
COCO annotation format. Data hosting and version control were managed through GitHub, utilizing Git for
seamless working between local and remote repositories.
At the end of the competition, we manually annotated a total of 820 images. These annotations amounted to
11,344 labels, distributed as follows: undamaged residential building (7951), undamaged commercial building
(2249), damaged residential building (907), and damaged commercial building (237).
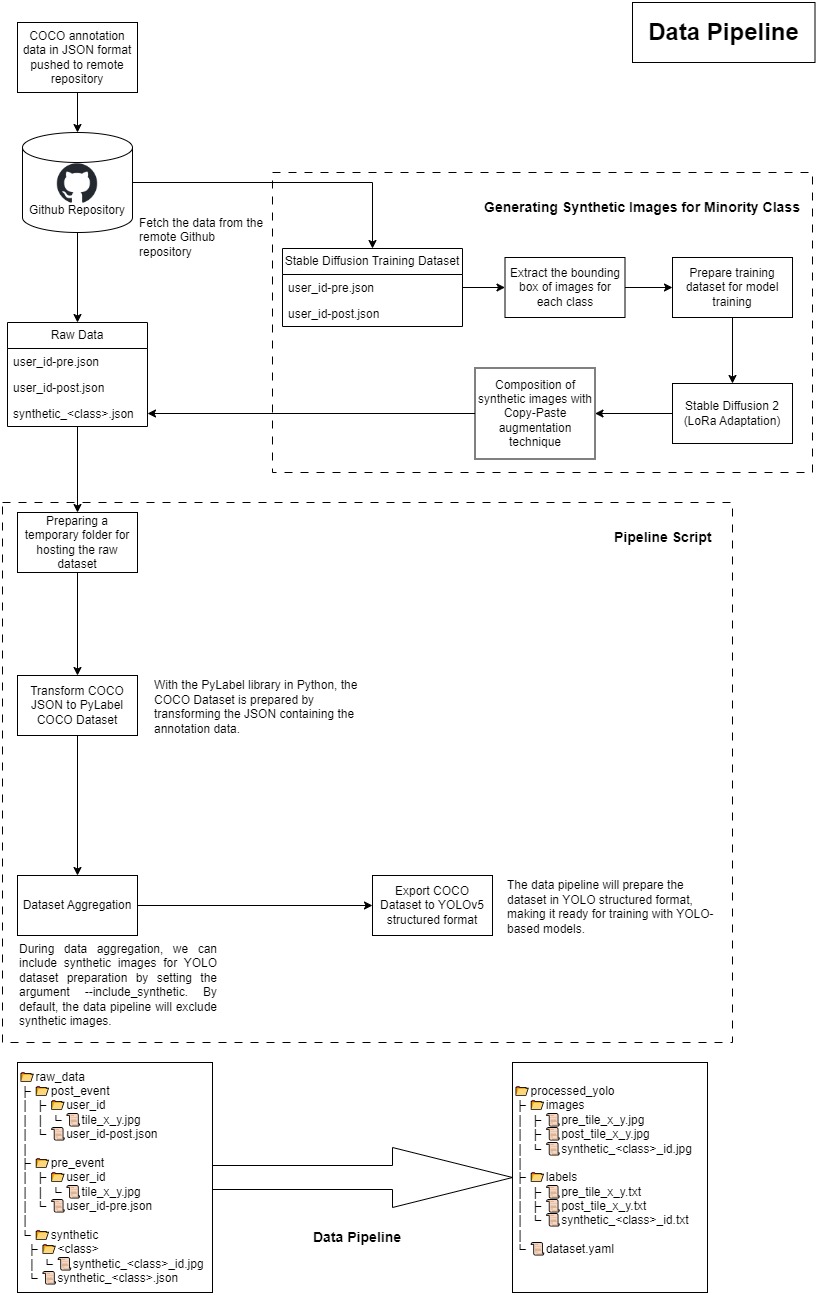
2. Data Pipeline: To streamline workflow efficiency, we developed a data pipeline for data
processing and training dataset preparation. This pipeline receives JSON files containing COCO annotation
format data and undergoes multiple stages of processing, including JSON to COCO PyLabel dataset
transformation, dataset aggregation from multiple inputs, and dataset cleaning. The pipeline ultimately
produces YOLO structured files optimized for training YOLO-based models.
3. Training Machine Learning Model: Effective training of the machine learning model
requires substantial hardware resources and CUDA acceleration for accelerated training. We trained our model
by leveraging Kaggle's cloud platform, which offers generous GPU access of 30 hours per week. Fine-tuning
was performed on YOLOv8 pre-trained models provided by Ultralytics, utilizing their high-level framework for
efficient model training and evaluation without the need for extensive architectural considerations.
4. Monitoring Machine Learning Training: WandB is used for experiment monitoring,
integrated with YOLOv8 training. This facilitated efficient experimentation with
various YOLO variants and hyperparameters, enabling us to track and evaluate multiple models effectively.
WandB served as a benchmarking tool, aiding in the selection of optimal model configurations and identifying
areas for improvement.
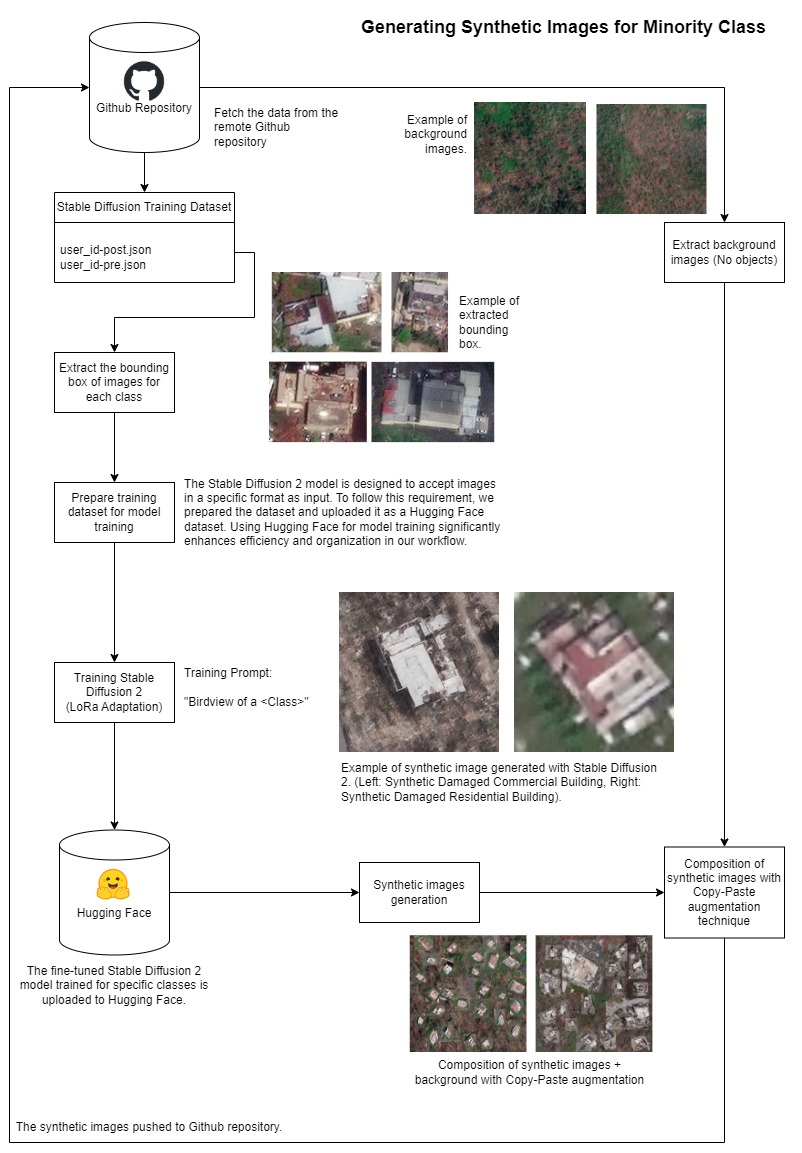
5. Synthetic Image Generation: To generate synthetic images, we chose to fine-tune the
Stable Diffusion 2 model by StabilityAI. Training dataset preparation involved extracting images with
bounding boxes for each class from our manually annotated dataset, used to fine-tune Stable Diffusion 2 for
synthetic image generation. Experimentation with different settings and hyperparameters, including LoRa
scale, training epochs was conducted, monitored using WandB. The dataset and trained Stable Diffusion models
are hosted on Hugging Face.
6. Evaluating the Trained Model: Trained models were evaluated based on metrics such as
mAP50, precision, and recall for each class. Confusion matrices, confidence curves, precision-recall curves,
and other metrics were utilized to assess model performance. Evaluation was conducted on WandB, enabling
comprehensive analysis to ensure effective predictions for each class.
7. Prediction of Trained Model: Evaluation of the trained model involved testing on 12
validation images provided by the organizers. Results from the detection from each of the validation image
(class, confidence score, bounding box coordinates) are saved in a .txt file and all the .txt files are
saved in a single .zip file. This zip file is uploaded to the challenge platform to get a score on the
ranking board. To enhance scores, prediction configurations were adjusted to minimize bounding box overlap
and optimize confidence thresholds.
 Hugging Face
Hugging Face
 WandB
WandB